Concourse: The Continuous Thing Doer
As someone who sees many different CI/CD tools every day, it takes a lot to get my attention. However, there is one tool that has had my attention for a few years now. That tool is Concourse. In this review, I will take a closer look at Concourse and give you my thoughts on the tool. I will cover the high-level overview, architecture, and pipelines in Concourse. Let’s dive in!
TL;DR
Concourse is a simple, yet powerful CI/CD tool that takes a unique approach to pipelines using declarative configuration files. It is a great choice for teams that want to automate their build, test, and deployment processes without the need for complex scripting.
- Website: https://concourse-ci.org
- Overall: 8/10
- Ease of Use: 7/10
- Features: 8/10
- Value: 8/10
- Documentation: 7/10
- Support: 8/10
High-Level Overview
Let’s look at Concourse from 10,000 feet. Concourse is a CI/CD tool that takes a unique approach to pipelines using declarative configuration files. It is designed to be generic and simple. There isn’t anything “flashy” and the mechanics behind it are quite simple. The mechanics of Concourse are resources, jobs, and tasks. Combining these together, you can create pipelines that automate your build, test, and deployment processes. Let’s break down each of these components.
Note: In this section we are only going to hit the high points of each component. We will get a more granular look at each component later in the post.
Resources
Resources are the what make a pipeline work in Concourse. These are all the inputs and outputs of jobs in your pipeline which are external to Concourse. They can be anything from Git repositories to Docker images to S3 buckets. Resources are defined in your pipeline configuration file and are versioned. This means that, as long as your external “source of truth” maintains the same level of versioning, (tags, branches, etc.), Your pipeline will always run exactly the same way.
Jobs
Jobs are the groupings of tasks in your pipeline. In some CI tools, a similar concept is a “stage.” Jobs can run independently of each other and can be triggered by different events. For example, you could have a job that runs every time a new commit is pushed to a Git repository, and another job that runs every night to perform some maintenance tasks. Jobs are defined in your pipeline configuration file and can have dependencies on other jobs.
Tasks
Tasks are the units of work within a job. There are, theoretically, an infinite number of tasks that can be run within a job. These tasks can be anything from running a script to deploying an application to a Kubernetes cluster. Tasks are defined in your pipeline configuration file and can have dependencies on other tasks.
Architecture
Concourse is built on a microservices architecture as well as uses Go as the primary language for the core components. The architecture of Concourse is broken down into two main components: The Web and The Worker. Each component has a specific role in the Concourse ecosystem. Here is a diagram from the Internals page that shows the architecture of Concourse:
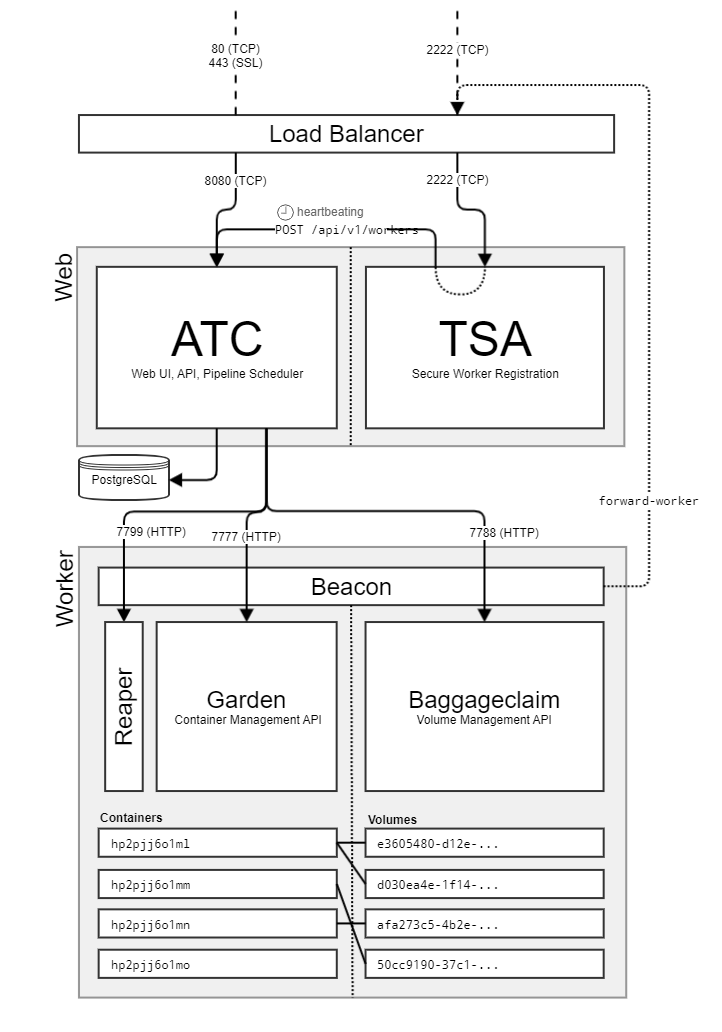
The Web
The web component of Concourse is the brains of the operation. It is responsible for managing the pipelines, scheduling the jobs, registering the workers, handling API requests, and is also the UI for Concourse. Another neat feature of Concourse is that, if you are in an environment where you either have your own front-end or you want to build your own front-end, you can run the web component in “headless” mode completely disabling the UI.
The web component can be broken down into two main components: The ATC and TSA. The ATC is the API that the web component uses to communicate with the workers. The TSA is the component that handles the authentication and authorization of the workers. This is a great feature for teams that want to ensure that only authorized workers can run tasks in their pipeline.
It’s important to note that Concourse does require PostgreSQL as a backing store for the web component. This is where all of the pipeline configurations, job statuses, and other metadata are stored.[4]
The Worker
Before we look at an example of a pipeline, let’s discuss how Concourse handles the execution of tasks. Concourse uses a concept called “workers.” These are groups of machines that are responsible for running the tasks in your pipeline. You can have multiple worker pools, each with different configurations, to handle different types of tasks. In your task, these worker pools are defined by the platform key in the task configuration. According to the Concourse documentation in the task-config schema, you can use any string value for the platform, as it is allowed so long as a worker advertises the same platform. However, in practice only linux, darwin, and windows are in use.
Each worker consists of a few components which are Beacon, Reaper, Garden, and Baggageclaim. The Beacon is the component that advertises the worker to the web component. The Reaper is the component that reaps the worker if it becomes unresponsive. Garden is the component that runs the tasks in containers. Baggageclaim is the component that manages the volumes for the containers.
Worker nodes are stateless and can be scaled horizontally to handle more tasks. This means that you can add more worker nodes to your worker pool to handle more tasks in parallel. This is a great feature for teams that need to run a large number of tasks in a short amount of time as well as want reproducibility in their tasks.
Additionally, worker nodes have another neat feature which is resource checks. Resource checks are the mechanism that Concourse uses to determine if a resource has changed and if a job should be triggered. This is a great feature for teams that want to ensure that their pipeline only runs when necessary.
Pipelines
The pipeline mechanics in Concourse are, in my biased opinion, excellently designed. You can easily build a complex pipeline that can handle all of your build, test, and deployment needs, and get as granular as necessary, while still being easy to read and understand.
Anatomy of a Pipeline
Pipelines in Concourse use YAML syntax. The pipeline itself is broken down into two primary sections: .resources and .jobs. Each holding their respective component we mentioned earlier.
It’s important to note that you don’t technically need to have a .resources section in your pipeline if you are not using any external resources. However, in most every case, you will want to have resources in your pipeline.
Another cool thing about resources, is that the Concourse community provides you with a vast array of resources that are available for you to use. You can find these resources on the Resource Types site. On top of this, if you can’t find one that you need, you can build your own custom resource. This is a great feature for teams that have specific needs for their pipeline.[5]
Each section will have it’s own schema that you will need to follow. For example, the .resources section will have a name, type, and source key. The .jobs section will have a name, public, and plan key.[1][2][3]
Let’s take a look at an example pipeline. For this case, we are going to use the git-triggered job example from the Concourse Examples page. Here is the pipeline configuration for reference:
---
resources:
- name: concourse-docs-git
type: git
icon: github
source:
uri: https://github.com/concourse/docs
jobs:
- name: job
public: true
plan:
- get: concourse-docs-git
trigger: true
- task: list-files
config:
inputs:
- name: concourse-docs-git
platform: linux
image_resource:
type: registry-image
source: { repository: busybox }
run:
path: ls
args: ["-la", "./concourse-docs-git"]
There are a few things that you can see going on in this pipeline. But let’s start at the top.
We have a single resource defined in the .resources section. This is the concourse-docs-git resource. Each resource must have a name, type, and source. In this case, the name is concourse-docs-git, the type is git, and the source is the URI of the GitHub repository.
Next, in the .jobs section, we have a job named job. Jobs only require a name and a plan. The plan of a job is very important as this is where the tasks that are to be used for the job are defined and where the resources are retrieved for the job.
For our plan in the job, let’s break it down a bit more.
- We are
get‘ing theconcourse-docs-git. This also has atrigger: truewhich means that this job will be triggered every time there is a new commit to the repository where the resource is located. - We are running a
tasknamedlist-files. You will also see that the task as a.config. This is where the functionality of the task is defined. Each task must have aplatform,image_resource, andrun. Theplatformis the what determines the worker pool the task will run on. Theimage_resourceis the Docker image that the task will run in. Therunis the command that will be run in the Docker container. Let’s dive in further on the Task’sconfig. We will read it from top to bottom..inputsis where the resources that are to be used in the task are defined. In this case, we are using theconcourse-docs-gitresource.- The
.platformislinux. This means that the task will run on a worker that advertises itself as alinuxworker. - The
.image_resourceis using aregistry-imagetype. In this case, it’s using thebusyboximage repository for it’ssource. - The
.runis the command that will be run in the Docker container. In this case, it’s runningls -la ./concourse-docs-git.
You can see that the pipeline configuration is very easy to read but can be very powerful and even down to the individual task, you can isolate and debug issues with ease.
Variables
Variables are also something that Concourse pipelines have available. They are referred to as “vars” in the context of the pipeline Configuration. Concourse has some built-in vars as well as the option to where you can define your own. I recommend checking out the vars documentation for more information on this.
One cool thing worth mentioning is that you can also use dynamic or static vars in your pipeline configuration. This means you can pre-define your vars or even call them at runtime.
var_sources
Note: As of writing,
var_sourcesis still marked experimental in the Concourse documentation for var_sources. However, the RFC which is mentioned has already been merged. I have also, personally, used this feature for awhile now and have not had any stability issues with it.
The .var_sources is where you can define vars that can be used in your pipeline configuration in a way that references them as a “source.” This allows you to do A LOT more with your pipeline while keeping your configuration clean and easy to read. Here is an example of a .var_sources section:
var_sources:
- name: cli
type: dummy
config:
vars:
version: "v1.0"
dev-build: "false"
- name: registryvar_sources
type: dummy
config:
vars:
host: "my.registry.mitchs.dev"
And you can use it like this:
resources:
- name: cli
type: registry-image
icon: docker
source:
repository: ((registry:host))/myapp/cli
tag: ((cli:version))
You can use this in both the .resources and .jobs sections of your pipeline configuration. I use this feature very often in my pipelines and it has saved me a lot of time and headaches!
You can also see that you can “group” various keys together so you can easily understand where your vars are coming from. This is great for multi-environment pipelines or even grouping similar vars together.
Job Visibility
Each job also has the capability to be public. For example, if your working on a project which has a public community, you can share certain jobs with the community, while keeping more sensitive or confidential jobs private. All that needs to be done to make a job public is to set public: true in the job configuration.
Web UI
The Web UI, in my opinion, is exactly what I want in a CI/CD tool. It gives you exactly what you need without any of the fluff. You can see your pipelines, jobs, and tasks in a very easy to read format. You can also see the status of each job and task in your pipeline. I’ll go ahead and break down a few things that I find very useful in the Web UI.
Pipeline View
One of the coolest features of the UI is the awesome pipeline view. You can see all of your pipelines in a very easy to read format. You can see the status of each job and task in your pipeline. You can also see the status of each resource in your pipeline. This is a great feature for teams that want to see the status of their pipeline at a glance.
Below, if you want to see the pipeline view in action, you can click the “Show Pipeline view” button. This will load the main Concourse pipeline view. Feel free to click around and see how the pipeline view works.
Job View
If you click in to a job, you can see the status of each task in the job. You can also see the logs of each task in the job. This is pretty standard in most CI/CD tools, but I feel that the “inline” perspective of the metadata and logs is very useful. Jenkins has “Stage View”[6] which is similar, and GitHub Actions has a similar view to what is available in Concourse but I feel that the GitHub Actions view just doesn’t “tick the box” for me like the Concourse view does.
fly CLI
The fly CLI is essential to working with Concourse. It is the primary way to interact with your Concourse instance. You can use it to set pipelines, trigger jobs, and view logs. The fly CLI is written in Go and is available for Windows, macOS, and Linux. You can download the fly CLI from the Concourse downloads page.
I won’t dive too deep into the fly CLI in this review as it’s very extensive, but I will say that it is very easy to use and has a lot of great features. I recommend checking out the fly CLI documentation for more information on this.
Auth
Concourse offers a pretty standard authentication and authorization system.
For auth you can use the built-in local auth provider, or you can use an external provider like GitHub, GitLab, or LDAP. I have found that the auth offering for concourse should be more than enough for most teams.
Teams
Teams are “groups” within Concourse. The cool thing about teams is that you can scope pipelines to a specific team or teams.
Note: The main team is the default team in Concourse. This is where all pipelines are created by default.
Roles
Roles are the permissions that exist within a team. You can assign roles to a user to give them the permissions that they need to interact with the pipelines for a team. An example (from the Concourse documentation) of what a roles configuration might look like:
roles:
- name: owner
github:
users: ["admin"]
- name: member
github:
teams: ["org:team"]
- name: viewer
github:
orgs: ["org"]
local:
users: ["visitor"]
You can see you can assign various auth providers to the roles. This is a great feature for when you are migrating from one provider to another or have teams that use different providers.
Roles can get complex, but I have found that the Concourse documentation does a great job of explaining how to set up roles for your teams. You can check out the Managing Team - Setting User Roles documentation for more information on this.
GitOps
GitOps is something that I personally find essential when it comes to CI/CD and hope that you do as well. GitOps and Concourse play hand-in-hand. Storing all of your pipelines and it’s resources in their own “source of truth” is a great way to ensure that your pipelines are always running the way you expect them to. This is a great feature for teams that want to ensure that their pipelines are always running the way they expect them to. Many tools in this space do have GitOps capabilities, but I feel that Concourse does it the best since you can quite literally define your entire pipeline in a single YAML file and version each and every one of your resources.
Areas for Improvement
While I think Concourse is a great tool, there are a few areas where I think it could be improved.
Easier Adoption
Don’t get me wrong, when I first started using Concourse, there was a bit of a learning curve. I think that Concourse could do a better job of making it easier for new users to get started. I think that the documentation could be improved to make it easier for new users to understand how to set up their pipelines. I feel that there are a lot of examples available. However, “real-world” examples are lacking. I think that if Concourse had more “real-world” examples available, it would make it easier for new users to get started.
That being said, once you understand the concepts of resources, jobs, and tasks, it’s very easy to build complex pipelines in Concourse and make them “production-ready.”
Continuous Delivery
Concourse is outstanding for Continuous Integration, but I feel that it could be improved for Continuous Delivery. And since it does market it self as a CI/CD tool[7], I feel that it could do a better job of providing more built-in features for Continuous Delivery. For example, it’s no competition when comparing it to ArgoCD or Flux for Continuous Delivery as both offer core CD features such as rollbacks, canary deployments, and blue-green deployments. While you can implement it yourself[8], I feel that until it’s on par with the other tools in this space, it’s not quite a great competitor in the CD space. I am thinking that these features could easily be implemented as resource types which would fit in perfectly with the Concourse concepts.
Conclusion
Concourse offers a well-rounded and robust tool that can turn your CI/CD processes into a well-oiled machine. It’s simple, yet powerful, and can handle complex pipelines with ease. The declarative configuration files make it easy to understand and maintain your pipelines. The microservices architecture allows for scalability and reliability. The web UI is clean and easy to use, and the fly CLI provides a powerful way to interact with your Concourse instance. The auth system is flexible and can be integrated with various providers. Overall, Concourse is a great choice for teams that want to automate their build, test, and deployment processes without the need for complex scripting.
I give Concourse an 8/10. It’s a solid tool that can handle your CI needs and is a great choice for teams that want to automate their build, test, and deployment processes. I recommend giving Concourse a try and seeing how it can help you streamline your CI/CD processes. Have you used Concourse before? What are your thoughts on it? Let me know in the comments below!
References
- This is the resource schema. https://concourse-ci.org/resources.html#schema.resource
- This is the job schema. https://concourse-ci.org/jobs.html#schema.job
- This is the task config schema. https://concourse-ci.org/tasks.html#schema.task-config
- If you are interested on specifics of how Concourse uses PostgreSQL, you can read more here. https://concourse-ci.org/postgresql-node.html
- If you are interested in building your own custom resource, you can read more here. https://concourse-ci.org/implementing-resource-types.html
- You can look at the
Core/jenkins/masterjobs “Stage View” for an example of what I am referring to here: https://ci.jenkins.io/job/Core/job/jenkins/job/master/ - According to the Concourse website:
Built on the simple mechanics of resources, tasks, and jobs, Concourse presents a general approach to automation that makes it great for CI/CD.
- An archived VMware repository has an example on how to implement blue-green deployments in Concourse: vmware-archive/concourse-pipeline-samples
Share on
Facebook LinkedInBuy me a coffee



Leave a comment